
AI video analysis has gone through three generations in about a decade — yet most teams are still using tools built for the first one. If you’ve ever used an AI video analyzer to tag a clip archive, pull a transcript, or asked a system “what happens in this scene?”, you’ve touched a different era of the same idea.
Whether you’re a creator, a marketer, a media team, or an engineer evaluating which video analysis AI fits modern workflows, here’s how it evolved, where it’s heading in 2026, and what “modern” actually means now.
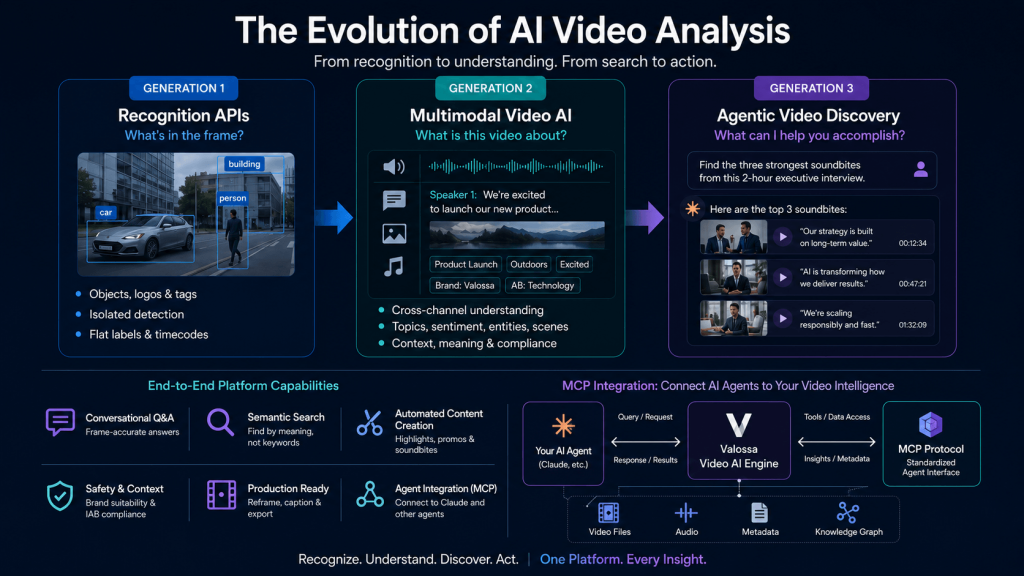
Generation 1: video recognition APIs (tags and labels)
The first wave of video content analysis was about recognition. You sent a video to a cloud API — services like AWS Rekognition, Google Cloud Video Intelligence, or Microsoft Azure Video Indexer — and got back flat labels: objects, logos, faces, on-screen text (OCR), and timecodes. For the first time you could index and search a library by what appeared in the footage instead of by filename.
But these video recognition online workflows hit a ceiling. A string of tags (“car,” “person,” “outdoor”) tells you what appeared — not what happened, what it meant, or whether it’s right for a brand. First-generation APIs made video searchable; they didn’t make it understandable. You still had to build the logic to interpret the tags.
Generation 2: multimodal video AI (context and meaning)
The second wave combined the signals. Instead of analyzing pixels alone, multimodal video AI reads the visuals, listens to speech and audio, reads on-screen text, and interprets them together — the way a person watching the video would. Speech becomes a speaker-separated transcript; scenes become described moments; topics, sentiment, named entities, and IAB content categories emerge from the combination, not from any single channel.
This is the leap from “what’s in the frame” to “what this video is about.” It’s what makes contextual ad placement, brand-safety screening, content moderation, and real search-inside-video possible. Valossa has built multimodal video intelligence at this level for over a decade — the engine behind products used by media companies, broadcasters and advertisers, including Valossa Transcribe Pro for transcripts and captions and Valossa Moderator for content safety.
Generation 3: agentic, conversational video understanding
The newest wave, reshaping the field in 2026, is agentic video understanding. Two things changed.
The conversational interface
Instead of reading a dashboard of tags, you talk to an AI that can watch videos and reason over them in natural language:
- “Which videos can I run a brand-safe ad against, and why?”
- “Pull the three strongest soundbites from this two-hour interview.”
- “Cut a 30-second vertical with captions around the product launch.”
The model interprets the question, works across the full multimodal analysis, and answers — or just does the task. It’s also how people now search for the capability: “which ai can analyze videos,” or simply “an AI where I can upload a video and ask questions.”
Autonomous, agentic workflows
The AI moves from answering to doing. Through open standards like the Model Context Protocol (MCP), agents such as Claude can call video understanding directly — search an archive, read a transcript, find highlights, run an agentic video-editing workflow, and export a finished clip — without a human clicking through a UI.
This also transforms content discovery. It’s retrieval-augmented generation (RAG) applied to video: instead of guessing from a transcript, the agent retrieves the exact moments, scene descriptions, speaker context and entities from your library and grounds its answers in them — RAG over multimodal video, not just text documents. Your archive stops being passive storage and becomes a queryable knowledge base your agents can reason over.
The difference that matters: earlier generations described video. Modern AI video analysis understands it and acts on it.
What modern AI video analysis looks like in practice
If you want an AI where you can upload videos and ask questions, a modern video-AI workflow should do more than extract text. It should:
- Answer questions about any video conversationally, with timestamped citations.
- Search by meaning across large libraries — by what’s seen, said, or shown on screen, not by filename.
- Surface the best parts — soundbites, highlights and promotable moments — automatically.
- Read context and safety — topics, IAB categories, sensitive content, and brand suitability.
- Produce, not just analyze — cut, reframe and caption clips natively, turning analysis into publishable media.
- Work through your AI agent — connect into your tools and agents via MCP.
That’s the line Valossa has built toward: Valossa Assistant for conversational understanding, Ad Scout for contextual and brand-safety analysis, and a live MCP server that lets Claude and other agents understand, search and export video programmatically. The same decade-long thread of video understanding — now agentic.
Moving beyond legacy frameworks
If your video analysis still means a list of object labels, you’re a generation or two behind what’s possible. Modern AI video analysis is conversational, multimodal and agentic — you ask, and it understands and acts. The field has shifted from tools that merely describe video to systems that understand and act on it, and it’s the most useful video AI has ever been.