
Valossa Assistant MCP Server — Video Understanding for Claude & AI Agents
Bring Valossa’s multimodal AI video analysis into Claude and your AI agents — ask your video library anything and get answers, soundbites, transcripts, metadata and finished clips. Connect once, upload videos, then just ask — across your whole library.
claude mcp add --transport http valossa https://mcp-assistant.valossa.com/mcp
Connect once, then just ask — across your whole library:
"Cut a 30-second vertical with captions from the best moments."
"Find the best brand-safe contextual ad moments for a car brand."
Three steps from video file to agentic video workflows
Add the server to your MCP client and sign in with OAuth (the server never sees your password).
Upload videos for analysis, then ask for clips and insights from your library in plain language.
Timestamped answers, soundbites, transcripts, metadata, chapters, summaries and ready-to-use clips. Runs on your existing plan’s quota.
Your agent does the asking → Valossa’s video agent does the watching, listening and understanding — and exports the finished clip.
It even hands results back in the format you need: clips, transcripts and captions from Valossa, plus FCPXML, CSV or JSON that Claude assembles for your editor or pipeline.
Claude Code:
```
claude mcp add --transport http valossa https://mcp-assistant.valossa.com/mcp
```
Other JSON-config clients:
```
{ "mcpServers": { "valossa": { "type": "http", "url": "https://mcp-assistant.valossa.com/mcp" } } }
```
Works with
Claude · Claude Code · Claude Desktop · Cursor · OpenCode · any MCP-compatible client.

Mst video tools stop at search; Valossa also exports finished, captioned, reframed clips.
EU-based & GDPR-compliant
Your uploaded content is stored and processed in the EEA and isn’t used to train our AI models unless you opt in.

A decade of in-house video AI (speech, visuals, audio, on-screen text, faces, moods, structure), not a GPT wrapper.
Me: Are there any sensitive scenes in this video?
Assistant:
Here are segments from the video containing violence, weapons, threats, explicit language, substance use, injury, death, and other sensitive material:
Dark injury scene
00:00:58 - 00:01:02
Very dark outdoor scene; ground is uneven; content involves blood, open wound, bruise (injury and violence present).
Ski resort gun threat
00:03:36 - 00:03:41
Outdoor dining at a ski resort; gloved hand holding a black revolver, very tense moment (weapons and threat present).
....
Give your AI agent video understanding
New to the space? See how AI video analysis has evolved
Prompt: "Find a scene with suspense and intrigue"
Response:
00:00:58 - 00:01:02: A man in a trench coat is threatening with a gun, ominous dark setting, harmful dialogue, suspenseful music, expressions of anger and displeasure.
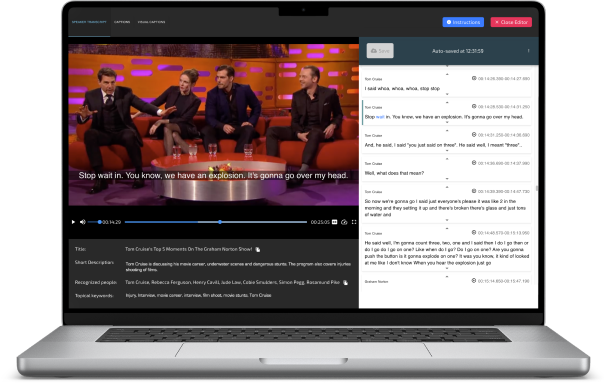
Not a developer or need an UI for your video agent? Try Valossa Assistant — a conversational agentic AI application for video analysis including RAG, clipping and prompt-based video task assignmnts. Ask questions about your videos, search transcripts, extract clips, and generate reports using natural language.
No code required. Upload a video and start asking. Assistant watches and listens through video content using Valossa AI and turns it into answers, insights, meta assets, text descriptions, clips — complex task automation.